

作者|赵赛坡
头图|视觉中国
距离 ChatGPT 正式亮相仅仅过去两个月,但以它却已经成为全球科技领域最热门的话题(或许没有之一)。从快速涌入的资本到海量而惊人的 Demo 演示再到一系列富有前瞻性的研究突破,通用人工智能的大门似乎正在被人类撬开……
本期 AI内参将结合春节期间的行业事件,进一步梳理围绕 ChatGPT 以及生成式 AI 的产业现状与值得关注的行业趋势。
资本风向
微软已经确认将向 OpenAI 注资“数十亿美元”,不过鉴于微软并未否认此前市场广泛传闻的 100 亿美元投资计划,我们有理由相信,接下来微软还会不断加大对 OpenAI 的投资。
这项投资进一步将 OpenAI 与微软绑定在一起,包括三个方面:
微软为 OpenAI 的基础研究提供资金支持;
微软会把 OpenAI 的研究成果集成到大量软件产品之中,包括但不限于 Office、Teams 等;
OpenAI 将使用微软的 Azure 云服务器;
此前多家媒体披露,包括知名投资人 Peter Thiel 在内的多家投资人或投资机构,都对投资 OpenAI 表达了浓厚的兴趣,资本市场为 OpenAI 的标的是 300 亿美元估值。
过去的 2022 年,基于 GPT-3、DALL-E、Stable Diffusion 以及 ChatGPT 等大模型的应用创新层出不穷,所谓“AI 正在吃掉软件”正是展示了当下软件开发范式的变化——从大模型中寻找灵感,下图是 a16z 投资合伙人 Jack Soslow 分享的 Stable Diffusion 发展速度:

生成式 AI 创业领域的一组融资数据也极具代表性:
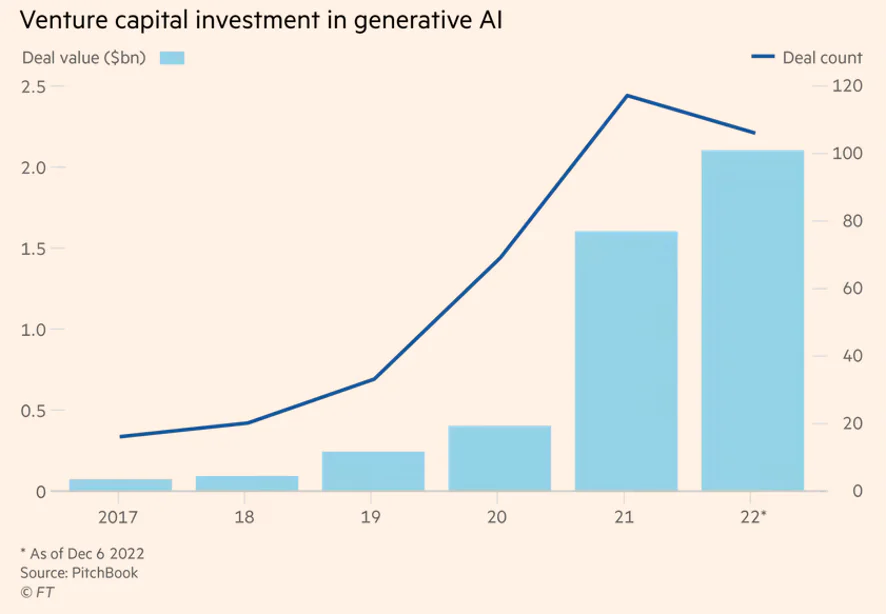
与此同时,当在线新闻网站 BuzzFeed 宣布引入 AI 编辑之后,公司股价一度暴涨 92%;而本周百度即将推出类 ChatGPT 的消息,也引发该公司股价大涨。这从一个侧面展现出资本市场对"生成式 AI"的疯狂程度。
但在知名风投机构 a16z 看来,现阶段的生成式 AI 并没有清晰的商业模式,这篇分析报告将该领域划分为三个纬度:
模型提供商,比如 OpenAI;
基于模型的应用开发商,比如市场上广泛存在的各类新应用;
基础设施提供商,比如英伟达或 AWS ,它们为上面两类公司提供基础设施服务;
就目前来看,前两类公司还处于大量投资(烧钱)的阶段,基础设施提供商目前是最大的赢家;中期来看,那些基于第三方模型开发应用的公司,也会逐渐转向使用自己的模型,这对诸如 OpenAI 这样的模型提供商并不是一个好消息。
观点与立场
Meta 公司首席 AI 科学家杨乐昆最近的观点引发热议,他在一个 Zoom 会议上表示,从基础研究的角度去看,ChatGPT 没有令人印象深刻的技术创新,其最大的"创新"是将现有的技术与体验进行了更好整合,带给用户以及开发者非常棒的体验。
杨乐昆的这个观点被某些媒体解读为是对 ChatGPT 的批判,但这更像是对业界炒作 ChatGPT 的回应,其中有几个关键点:
OpenAI 并不是业界唯一一家利用海量数据进行模型创新的公司,Google、Meta 等公司也在做类似的事情,还有众多创业公司;
ChatGPT 的底层技术来自于 Google 提出的 Transformer 架构,同时还使用了大量在 Google 内部使用(由 DeepMind 发明)的强化学习技术;
正如杨乐昆反复强调的,这个领域并没有所谓“秘密技术”,大量开源的架构、模型以及数十年来公开的论文等,为 ChatGPT 的出现创造了良好的基础,"它不是真空出现的"。
结合杨乐昆的观点,再去翻最新一期 Fortune 杂志对于 OpenAI 公司的特写,或许能有更清醒的认识,这篇长文采访了包括 OpenAI CEO Sam Altman 在内的众多 OpenAI 内部员工,能够一窥 ChatGPT 的前生与今世。
在诸如 ChatGPT 这类大语言模型的应用场景里,如何让模型呈现出“事实”是一个巨大的技术挑战,比如科技媒体 CNET 在使用大语言模型发布新闻的实验之后发现,人类编辑不得不花时间去修正新闻里的内容错误。
如果你对这个话题感兴趣,这篇来自以色列 AI 创业公司 AI21 Labs 首席科学家约亚夫 莱文的访谈很值得一读,你会看到业界正在通过怎样的方法攻克这一技术难题。
新应用场景与争议
《自然》杂志网站上周发表了一篇基于生成式 AI 技术设计全新蛋白质的研究。
这是最近非常火热的研究方向。自然语言和蛋白质在结构上非常相似,氨基酸以多种组合方式排列,形成生物体内具有特定功能的结构,类似于单词以不同的组合方式形成表达某些事实的句子。
加州创业公司 Profluent Bio 与加利福尼亚大学旧金山分校共同完成了这项研究,他们创建了一个名为“ProGen”的大模型,使用超过 2.8 亿条蛋白质序列的数据进行训练,实验室测试的数据显示,生成的一些酶(具有催化作用的蛋白质)与自然界中发现的酶虽然在序列上明显不同,但具有同样的作用。
这个研究方向对于加速药物发现具有重要意义:
通过生成的蛋白质寻找与现有药物同样有效但副作用较少的药物;
通过生成新的蛋白质,避免专利影响,从而降低新药物的开发成本;
该领域还有几个值得关注的公司:
Generate Biomedicines 公司:总部位于麻省,已完成 4.2 亿美元的融资;
Absci 公司:一家利用深度学习加速药物发现的公司,2021 年已上市,市值 2.9 亿美元左右;
Isomorphic Labs:这是 DeepMind 分拆出来的一个实验室,由 DeepMind 创始人 Demis Hassabis 负责;
Google 日前展示了一个利用文本生成音乐的模型 MusicLM,与诸如 GPT-3 等模型类似,MusicLM 也使用了 Transformer 架构。
根据其论文,MusicLM 使用超过 28 万小时的数据进行训练,用户通过自然语言(文本)进行描述,系统可生成最高 24kHz 的音乐。另外,该模型还允许用户使用唱歌、吹口哨或哼唱曲子等形式生成音乐,这将极大改变音乐内容的制作方式。
不过 Google 已明确表示,鉴于其可能引发版权争议,他们选择暂时不公开发布这个模型。
事实上,围绕大模型的版权争议还存在于训练数据是否合法,目前的几项法律诉讼基本都围绕这个方面:
正如 FT 评论 Getty 起诉 Stability AI 公司所言,Getty 选择在全球版权管理最严格的英国发起诉讼,也是对英国法律体系的一次考验,法官如何认定生成式 AI 模型里的数据、版权归属,或将为全球其他国家和地区的类似法律诉讼提供参考。
法律纠纷之外,不同行业对于是否应该使用、如何使用 ChatGPT 的态度也存在巨大分歧,比如教育领域,美国多所学校和教育机构都限制使用生成式 AI 产品,甚至不允许学生在学校网络里访问 OpenAI 网站。
另一个“教育”领域——沃顿商学院——则给出了不同的思考:当 ChatGPT 能够应对 MBA 考试的时候,我们是否应该重新审视教育方法与体制?
沃顿商学院教授 Christian Terwiesch 为此发布了一篇报告,展示了 ChatGPT 在 MBA 运营管理课程期末考试中的表现。他认为,当下 ChatGPT 只能通过标准化的模板处理问题,但它非常善于根据人类提示修改它的答案。也就是说,人类可以通过调整提示词,优化 ChatGPT 的答案,这对改变当下 MBA 教育体系意义重大。
这份研究引发众多学者的反应:
密歇根大学罗斯商学院教授 Jerry Davis:整个教育事业正受到这种挑战,而且这种挑战只会越来越大,现在是时候彻底重新思考(教育体系)了;
帝国理工大学商学院院长 Francisco Veloso:我们有一个工作小组正在评估 ChatGPT 和类似工具带来的影响;
最后分享一个关于中文类 ChatGPT 产品的发展思考。百度最早将于 3 月份推出类 ChatGPT 的产品,考虑到中国互联网的信息管理环境,百度如何处理或者准确地说过滤所谓“非法信息”,这会成为未来中文大语言模型落地的重要参照物。
更进一步,结合 TechCrunch 这篇报道,在芯片禁售令的影响下,中国公司将越来越难获得最先进的 AI 芯片,中文大语言模型的发展是否会受到影响?
当然,就像我在春节前的一篇会员通讯里所指:这类产品需要长期而巨大的资金投入(想象一下几万张英伟达 GPU 工作的场景)以及坚定的长期战略,这与中国互联网公司的风格并不一致……
或许我是在杞人忧天了。
评论