

虎嗅注:张智威是Google两位创始人佩奇(Larry Page)和布林(Sergey Brin)斯坦福同学,出身一个实验室,在98年Google刚创立的时候,曾一再邀请张智威加入。而张智威真正加入的时间是在2006年,负责搜索与社区产品,2010年负责全球移动技术创新的研发。在谷歌期间,他还给经费支持人工智能专家李飞飞的研究,直接支持见证了人工智能核心技术的发展。1999年8月,获得斯坦福大学电机工程博士学位之后,张智威教授受聘于加利福尼亚大学圣巴巴拉分校电子和计算机工程系。2003年3月,他获得终身职位,并于2006年晋升为电子工程学正教授。
目前,张智威是HTC 研发及医疗总裁,HTC北京的新项目,是他从零到一、一手搭建的,而他目前最关注的方向AI技术在医疗领域的应用。
本期圆桌的专业性很强,阅读本文要具备一定的专业知识储备。本文从人工智能的多种学习方法入手,阐述了当数据量不足时,如何通过有限的数据进行学习的这一难题;本文也从商业角度进行分析,讨论2b与2c两种模式,AR与VR技术的进步也为人工智能医疗提供了新思路。
(为了表意的准确性,保留现场分享中的部分英文,以下是活动现场实录)
今天我的讲话你们随时可以打断,这是个非正式的分享,主题围绕人工智能,VR可能也会提及。
首先看医疗,最近人工智能被炒得非常火热,但这个名词绝对不是最近才出来的,二三十年前就有了。大概在过去两年前你跟别人说你在做人工智能,别人基本上会耻笑你,一直到2年前人工智能发起烧来。关键是两个原因,一个是scale of data(数据规模),另外一个是scale of computation(计算资源规模),因为现在加上GPU(图形处理器,Graphics Processing Unit的缩写)之后,加上算法的优化,计算速度有了很大的提高。
像Hinton(Deep learning领域著名专家)讲的,现在的计算速度跟十年前比起来基本上是一百万倍。所以说因为数据多了,再加上速度快了,才有今天的进步。那讲到数据呢,我是挺低调,但这是事实,最近两三年为什么忽然人工智能起来,实在2012年AlexNet(图像分解模型)用了image net(图像网络)这套data set(内存数据库),这是李飞飞在斯坦福当教授的时候请很多亚马逊的用户标注的图片,大概标注了 1500万张,这个项目是谁给他钱的呢?是我,20万美金,谷歌给他的,但是我们也不会大张旗鼓地讲这些事情。
分享这些是想说整个大数据跟AI的历史,我们都参与了。(也是虎嗅邀请张博士分享人工智能从哪来的原因)今天讲AI我们还是一个非常保守的态度,就像刚刚大家说的,AI在大数据的基础下,今天运行得比以前好,但是在很多的场景之下AI还是有问题的。
成本、品质、普及率的铁三角
那先讲医疗,这个是一百多年前传教士到台湾去开一家医院,那个时候的手术室长这个样子,一百多年来手术设备的进步是毋庸置疑的,但是医疗的基础还是有很大的问题。美国最近在炒医疗,因为医疗每年的花费是GDP的20%。国内虽然是7%,但是也在往20%的方向走。
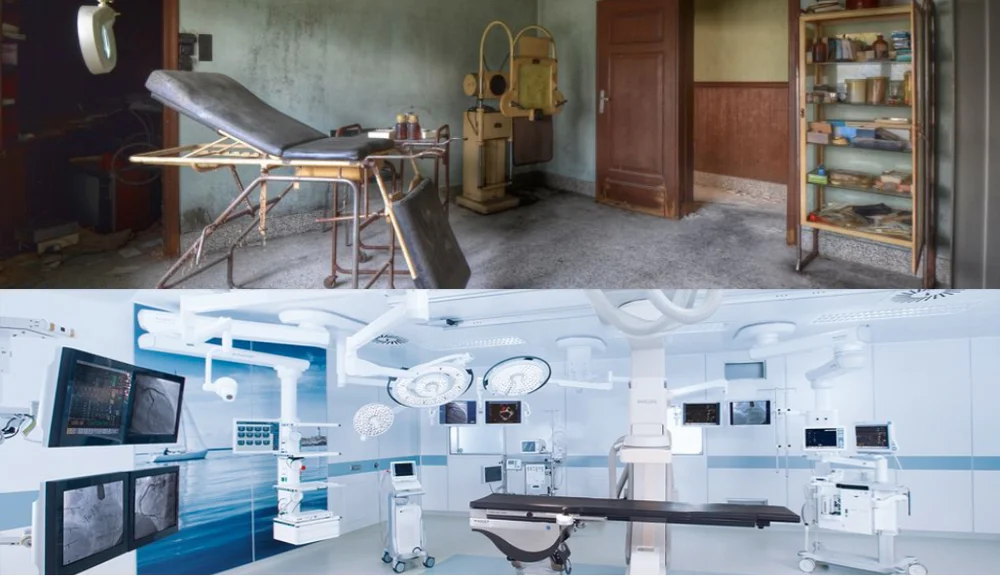
那为什么医疗真正的基础没有进步,主要是由三个很重要的因素造成的:一个是成本,一个是品质,一个是普及率。有人说是叫铁三角,就是说某一项进步,另外两个会拖着它,没办法往前走。比如说我希望成本进步,那品质可能就退步;如果我希望普及,那肯定要花钱嘛,所以普及以后品质也会下降。
美国公司要帮每个员工付的保险是一万美金一年,这是非常大的数字。46%的美国人生病不去看医生,在家里查一查数据或者买一些药就算了,另外现在全世界25亿的民众没有被医疗覆盖,即使有医疗设备的地方,医生跟病人的比是1:2000,这些问题还是挺大的。
甚至在美国,每年也有120万人次被误诊,所以即使在比较先进的国家,品质跟成本还有普及率都是很大的问题。原来我们以为这是个死局,没有办法让三个一起进步,但是最近我们发现有新的机会。
数据让医疗发生在“大医院”之外
我们先看比较先进的地方,比方说美国各大城市在盖大型医院。之前在硅谷跑来跑去的时候大家就觉得大型医院的模型可能不正确,因为原本不需要这么大的成本就可以支撑医疗体系了,所以现在在硅谷,包括Google在内,很多VC(风险投资人)说如果让他们重新在医疗领域投资他们不会走大医院模型。那他们选用什么模型呢?下面就给大家解释一下。
在生病的时候是reactive model(响应式模型),也就是说不生病一般人不会去医院。一旦亚健康了病人去问诊,医生可能说病人去做个检验,检验科能排在下一周,检验结果出来后医生再确诊。即使确诊了也不一定是正确的诊断,病人就拿药回家了,之后如果没好再去找医生。在这种情况下医院给的确诊就已经超过两起了,也不跟进,这就是问题。
那我们希望整个模型有个突破,我们希望有一个disruptive model(颠覆性模型,来自于disruptive innovation颠覆性创新),这个模型为什么可以实现,讲到这个非常有意思,尤其在中国过去一二十年,有一个非常颠覆性的创新或者说改变。
中国大概是1980年-1990年开始布置电话,如果说跟着美国的模型到处去架设有线电话,那成本太大,但还好中国直接绕过有线的模型,直接到无线。那中国是不是可以绕过美国建造大型医院的模型,直接建一个新的模型。因为现在有云端,假设现有在家里实时监测患者或用户的设备,是不是就有希望?
我现在放的是HTC跟Under Amour合作的叫HealthBox(一款健身套件产品,包括一个智能手环、一个心脏监测手环和一个智能体重计)。

我们要做一个设备,叫Tricoder(来源于《星际迷航》电影里的神奇设备)。如果在家里有这种监控设备,监测用户的健康状况,然后云端收到信息进行分类,如果有问题,云端会给用户发送一个警告,说你现在变得亚健康了。在用户觉得不舒服之前就已经收到警告,医院也收到一个讯息,可以邀请用户做检查。
医生说可能再做一两样测试,数据分析完通知医生,如果有问题再通知用户去看病,这个时候确诊就变得比较准确。这个模型不是reactive(应激性),而是proactive(先发性),就是说在疾病还没有发生之前,数据已经传入云端,医生可以预测你的病症,这是第一个不同的地方。
第二个不同的地方,因为有云端,所以用户不见得要进大医院。很多事情可以在家里做,通过云端分析用户的数据,再去通知医生,医生也不见得要在同一个城市,所以这个模型不止是完全适用,它也是一个proactive(先发性)的系统。
最近有两个比较有趣的两个大案子,第一个把AI变得非常火红,有了AI之后呢,我们有可能做到precision medicine(精准医疗)。那怎么可以做到呢?待会儿可以讲的比较细一点。还有一个案子就是AR跟VR,有了它们直呼,我们可以做到precision surgery(精准手术),待会儿放一个片子,告诉大家怎么用AR技术开刀。
我们去医院开刀,常常有人不幸,家人或者朋友就过世了,通常医院给人的感觉是人可能病得很严重,再精进的医术可能也没有办法救他,事实上真的如此呢?还是开刀的技术可以再进一步提高?我们最近做研究,真的觉得开刀技术有限,甚至可以说是差得非常离谱。有的病人可能是死于非命,也许是切错管线,不应该切到动脉却切到,或者切到尿管,家人会被告知吗?绝对不会。
我们现在也尝试进入医疗器材领域,成立的一家公司的名字叫DQ,D是Deep Learning,Q是Quest。这个很小的盒子5磅不到,现在的医材,如果要把5磅的东西集成起来,是很不容易的。

Xprice,让不可能变成可能的基金
我先介绍一家公司,它是很多比赛的赞助商,叫Xprice,它12年前在美国成立,创始人团队在美国找一些非常牛的CEO,包括贝索斯(美国亚马逊CEO)。Google的创始人在内的好多大牛都捐了很多钱给这个基金,这个基金的使命就是“让不可能变成可能”,它觉得如果说让大公司去做一些调研,都是很快就要盈利的,所以比较短视。它就鼓励去做一些创新性的研究,譬如说它的第一个比赛在12年前,是送人到到太空去旅行,这个做了十几年之后,现在有一两家公司像那个Virgin Airline(维珍航空),最近开始做一些实验有偿送人去太空旅行,已经很多人报名。
第二个比赛现在大家一定觉得很好笑,这有什么好比的,是无人驾驶汽车,那个时候每年都办无人驾驶汽车竞赛,但是几十年了都没什么进展,它(Xprice)出来办之后说第一名我给500万美金,所以很多学校前赴后继地愿意花很多钱去做,之后斯坦福的教授叫谷歌Project X(谷歌专门研发炫酷项目的部门)去开发无人车,把整个产业给带起来了。
第三个比赛是DNA sequencing(DNA排序),2005年我刚来国内的时候,跟华大基因基因排序中心做一个交流。那时候他对谷歌很有兴趣,当时他们刚在《Nature》(英国著名杂志,世界上最早的国际性科技期刊)发表了一篇论文,首次排序亚洲人的DNA,他们说花了他们一年,他们说谷歌可以把他们一年缩短成几个月,然后Xprice那边给奖励看三年之内能不能把时间缩短到几分钟,结果那个比赛到第二年就结束了,因为外面没有参加比赛的有一家公司已经做到低于一分钟了。
那我们这个比赛大概在五年前,主办方说非洲的落后地区根本就没有医疗设备,你开发一个便捷多功能的医疗设备。我想大家看过《星际迷航》,里面有个机器叫做Tricoder,我们的机器就是用的Tricoder这个名字。这个Tricoder有什么功用呢?Star Trek是模拟2223年的情况,要诊断疾病的时候,就拿那个盒子去扫描一下,就知道病人大概患了什么病,然后再拿这个盒子扫描一下,就直接帮病人治病,两百年之后希望这个能够成为现实。

Xprice在5年前就说,你们可不可以做一个5磅以下的小盒子,可以监测15种疾病。此外还得可以监测5种不同的重要数据:血液、血压、心跳、体温、血氧,以及呼吸频率。这个比赛我们得了第二名,上个月4月22号我们才去好莱坞领奖的。
Tricoder:家用医疗设备的未来?
好,现在我们把这个盒子打开,盒子上面不意外就是个手机,没有必要做展示了,直接把HTC手机放上去,用手机两个功能非常明显,一个是拍照,一个手机本地数据上传云端。然后呢,我们把这个box打开,分成三个不同的部分,最左边的部分大家看到很多颜色,有很多小的盒子,这些是验尿、验血的,右边有几个镜头,那是测试皮肤病跟中耳炎的,下面这些都是重要数据,右边这些分别是测体温的,测血压的,测血氧的。
下一张幻灯片比较细节,展示了我们能够测试哪15种疾病,这下面像是一个镜头的镜座,换了不同的镜头之后呢,这上面有一个比较平的镜头可以检测黑色素瘤。比较尖的镜头可以放耳朵里头,它可以检测中耳炎,后来我们也做了扁桃体检测设备,放在嘴巴里面就可以。有验尿道感染,我们有很多试纸试片,像糖尿病、贫血症、还有HIV、肝病等等都可以测试出来。
这些重要数据,血压、ECG(心电图)、体温、呼吸频率、血氧,五个组合起来可以检测三种不同的疾病,譬如说高血压、心律不整,以及睡眠呼吸中止症,最后一个是叫COPD(肺部气竭症),一个5磅的设备可以做到这么多的事情。
我们看到这边有两个摄像头,你再放第三个检测扁桃腺的也是没问题的。然后你把他们接起来之后,譬如说中耳炎,往耳朵里面照个相,然后照片传导到云端,云端给出分类。但是你不送到云端,在手机上分类一样可以做,那这个比赛为什么要送到云端,因为要确认没人作弊,云端它可以审查每个人上传的数据。
Sparse Coding:数据量不够可以换一种思路
用内置的镜头,黑色素瘤、湿疹、各种藓都可以识别。接下来大家就会问到怎么做到自动侦测,因为黑色素瘤和普通良性的痣很像。我们去找医生要一些黑色素瘤的照片,收集数据后,丢进监督学习的算法里去训练,是不是就可以运行了,答案大概没希望,为什么?一方面是生病的人不是很多,像我们当时去医院收集中耳炎的数据就拿到一千多张,数据量不够怎么去做训练呢?
我们团队里面都不是医生,有学统计的,有学计算机的,那我们就只好去求医生告诉我们中耳炎的特征是什么,医生实际上也讲不清楚,他们说有一点红肿,可能发黑紫色,跟着医生的指示我们就开始做传统的人类基因特征。这个案例说明,想要做医疗设备,第一必须要有相关领域的专家教你怎么抽特征值,第二要解决small data的问题。
现在把解决方案跟大家传达一下。我们基本上就拿网络图片做一个基础训练,大家一定觉得很荒谬:第一,我们收集数据就跟在百度上搜索图片一样,就锅碗瓢盆啊,车子啊,人脸啊,这些跟疾病毫无关系的图。把这些照片拿过来之后,然后我们用CNN(卷积神经网络)做两件事,首先把原来的一千多张,医生告诉我们的哪些中耳炎,哪些不是中耳炎,丢到CNN里面做训练,准确率只能达到70%,因为数据量不够;第二件事我们就把从网络上搜集来的几千万张照片,先做一个无监督学习(事先没有任何训练数据样本,需要直接对数据进行建模)。无监督学习是非常痛苦的,拿到数据不容易,要请医生标注也不容易。
怎么把它变成无监督呢,其他图片跟中耳炎无关,你也不希望每个图片都去打标签,它到底是车子还是锅碗瓢盆,这之后没办法成规模的。当初我在Google里赞助人李飞飞标注那个项目,25万美金,她也花了很多时间找amazon mechanical turk(亚马逊提供标注数据服务的平台)的用户去做标注,把这个问题变成一个编程的问题,图片进来之后做对比,原图进来大概都是几万个像素,然后变成jpg格式,把它压缩,做一个code book(编码本),做完code book你再压缩再还原,做code book的pipe line(通俗地讲是pipe line是一种流水线模版,一般由客户提供数据,AI公司提供pipe line,针对不同类型的数据,pipe line是不一样的)是完全不需要监督的。
知识链接:Amazon mechanical Turk是一个众包的互联网市场,可以使个人和企业来协调人类智能执行计算机目前无法做的任务。通俗来说,众包模式就是利用低廉的价格请网络用户来做某一件事,可以是标注数据,类似于不干坏事儿的网络水军。
(Amazon mechanical Turk页面展示)
关键无监督有一个优势,你可以有海量的数据,这个海量数据是没有限制的,等到你有这个code book之后呢,你把原来的照片做编程,那和传统编程不一样,这是sparse coding(稀疏编程)。现在sparse coding大家没有太注意,都一直在想CNN,其实neutral network(自然网络)、 deep learning(深度学习)、sparse coding(稀疏编程)跟CNN在理论上是可以接起来的。那如果大家有兴趣的话,上海理工经济学院,有一个叫马邑(音)的,他现在也是HTC的顾问,他出了一本书讲得非常清楚,那我们现在简单讲一下。
你出来的这个vector(向量)是一个非常高维度的vector,比原来图片的纬度还高, sparse coding是把图片丢进来之后,vector里面有value(值)的,非零的数字、元素变得非常非常少,非常稀疏。关键就是稀疏,出来的vector里面大部分都是0,有少部分有值。这有点像神经网络最后训练出来的那些很大的网络,但大部分都是0,很少数的是有weighs(值),那这个东西拿出来我们怎么用呢?所以原来那个code book跟中耳炎没关,完全是网络图片拿过来,用code book(编码本)来解码中耳炎图片。所以我现在拿一张中耳炎图片,我把它当成sparse coding,编码完之后新的feature vector(特征向量)出来,拿这个feature vector再丢进CNN做训练。
讲一下两个区别。
第一,原来是中耳炎的图片是直接丢进去的,只有70%的准确;现在我是把中耳炎的照片经过大数据帮我做完code book(编码本),编码之后把feature vector(特征向量)丢进来做完训练,准确率居然达到91%。这令人非常震惊,原来我们求着医生告诉我们怎么去标注基因特征的时候,准确率也只有80%。但现在拿一堆牛头不对马嘴的照片作为大数据,做完无监督学习之后,总结出来一个code book,然后你把中耳炎的图片编码后再丢进CNN的路径,居然准确率从70%增加到91%。
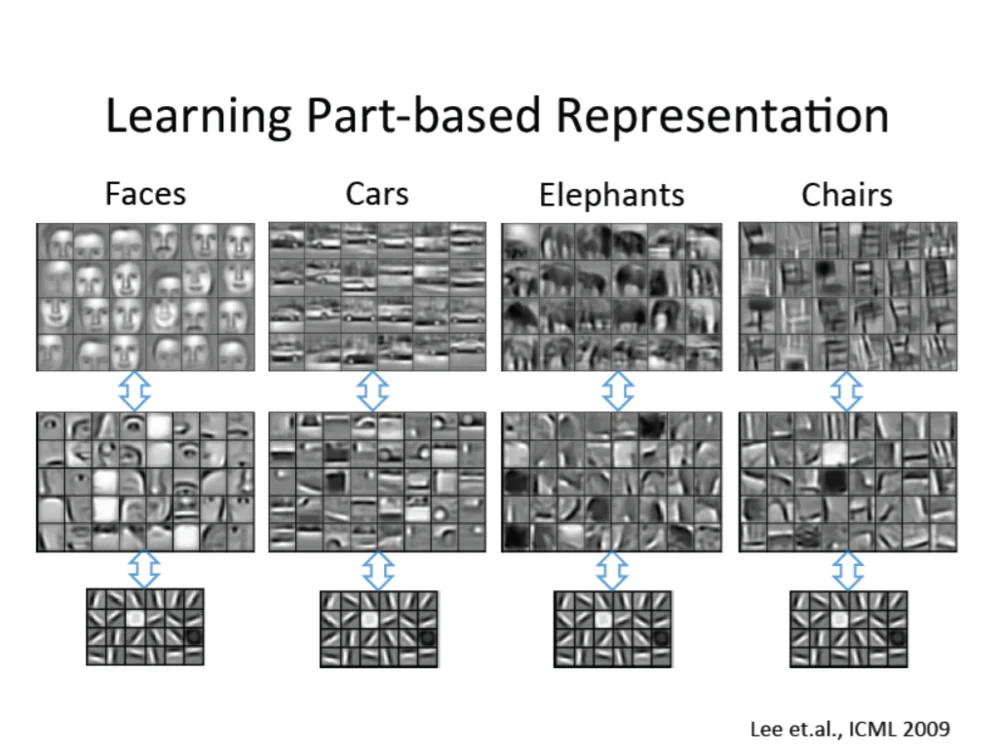
第二,解释为什么sparse coding(稀疏编程)会起作用。我们也想了半天,但是呢,我觉得吴恩达(百度前首席科学家)2009年发了一篇论文,用深度学习去分类不同的物体,比如说四个物体,人脸、汽车、大象跟椅子,这个图片只是解释为什么会起作用,最高的神经元是你的目标物体,语意上没有问题,然后去视觉化中间的层,学人脸的话中间层是脸的一些部分,眼睛鼻子嘴巴,如果是车子的话,学到的是门或者轮胎等等,那这个图片最终是看下面这层,它学到的东西都一样,都是最基础的特征,或者是角或者是边或者是颜色等等。
这就给我们一个启发:从互联网上抓这么多莫名其妙的照片进来,我学了一堆中间的没有用的特征,但是我可以用最下面这些层,因为最下面这些层不管是不是中耳炎都长得完全一样。
也就是说,最下面一层训练出来是直接有用的, sparse coding(稀疏编程)就是用最下面一层做编码,拿到feature vector(特征向量)之后建上面两层,我们建上面这一层不需要太多大数据,不需要100万张,1000万张,甚至1000张就达到刚刚91%的准确率。
杨强在香港科技大学大概做了一二十年的迁移学习,那时候我还跟他做过一段时间同事,因为那时候我客座,我还笑他说你这个迁移学习完全不靠谱嘛,牛头不对马嘴。但经历了这个例子不得不对他拜服,也就是说如果你能找到一个大数据源,你可以把知识转移到一个新的目标领域,那这个时候你可以用一个(无意义的)大数据去救一个(目标明确的)小数据的问题。
Source domain(源域——无意义的大数据)跟目标领域要有什么关系?要有数学关系。他中间如果没有关系的话,你还真是完全没有办法转移编码,所以在图片方面刚好很幸运,我们观察最基础的层就可以。这个是可以解释的,我们前面这几个层就只管edge detection(边缘检测),我们可能做的是rotation invariance edge detection(旋转不变性边缘检测),或者是scale invariance edge detection(规模不变性边缘检测),我只要有足够多的数据,我把下面最基础的一层学出来就不用再建下面的层,直接建上面的层。
这个原理我们用可视化的方式来表达,下面这层密码本是可以解释的,那上面我们借到其他图片的特征,如果最上面如果被认定为中耳炎,有哪些神经元被启动,有透明变形虫的,还有一些甲虫。即使我跟你不是完全相似,只要有相像性,在这种架构之后的特征也能被借用。这个例子就给大家非常振奋人心,也就是说只要是图片化的数据,这个路径在医疗方面是起作用的,当然我们现在做的是比较前瞻的研究。
我给大家一些提问的时间。
问:迁移学习是可以应用到任何一个领域,还是说有些目标领域效果会更好?
答:只要在图片领域,不管是X光图片还是中耳炎图片, transfer link(转移链接)都是有效的。另一个反例,让我比较遗憾的,就是心电图,心电图这个领域非常难,现在世界上的学习案例只有两个数据库,一个是哈佛的,一个是MIT的,各100例。为什么这么难呢?
第一个原因,不是每个病人都有症状,症状发生的时候也只有一两个小时,心脏跳一下我就标一下,数据非常稀少。现在全世界的数据只有200例,所以我们在台北找了非常有名的医生来帮忙,但即使医学专家进来了,心跳一下下去标注量也很大,我们标了半天,也许今年年终会从200例增加到500例,但仍然属于“小数据”的范畴。
第二个问题是在这个领域要找什么去转化,我们手法还没找到。心跳跟哪一种跳动的数据相似?我们两三年前觉得音乐很相似,或者说对话,那不是到处都是嘛,结果做了两三年,同事们每天都灰头土脸的,找不到统计的关联性。但是一旦找到,那就是金矿。
从Alpha Go到Alpha Cure:增强学习的应用
那我们接下来讲另外一个主题,很多人都知道Alpha GO,所以细节没有必要赘述了。最近 Alpha Go的CEO在剑桥演讲,里面讲说机器学习可以分为三种,一个就是经验学习,也就是监督学习,你把你的经验标注好丢进去学习;然后刚刚我们也讲了迁移学习,迁移学习在少数的案例里会有效果;最后一个是Alpha Go比较成功的,它用的是通用学习,但我们刚刚也提到,并不是每一个都能运行。
Alpha Go给我们一个启发是,比方说你今天已经学会打篮球了,然后去学打网球的时有些基本的事情就不用学了;或者说两岁的小孩子你教他看图他很可能看不懂,大概等到七八岁,他看了很多图了,你再让他看其他图片,他就会学得很快。那显然有些东西被转化,只是我们这边怎么去抓取呢。Alpha Go使用通用学习的这种理念,方式就是增强学习。
这个模型就是说有个agent(主体),跟环境有互动,然后我有个动作,环境的状态会改变,在这里面发现规律,比如说下棋的时候这个状态比较能赢,这就是增强学习的模型。
Alpha Go用增强学习建了两个网络,一个叫决策网络,一个叫数字网络,因为今天已经有一些专家在这边了,我就不再赘述。那关键是这两个网络对Alpha GO 最大的效益是产生了无限多的训练数据,怎么去产生呢?
第一个,决策网络不见得每一次在决策的时候做最好的决策。它使用MCMC(Markov Chain Monte Carlo随机采样方法)采样,它故意做错误的决定,每个主体的决定不见得正确,所以说它可以把一个最好的棋士变成一百多万个不同的棋士。然后它有一个价值网络,每次要怎么去提升这个棋谱上的胜率,然后它去打乱一些值,故意去走错几步,这样的好处是它可以刺激出来很多棋士。每个棋士下棋的价值体系不太一样,决策网络会故意走一些很疯狂的棋路,然后产生非常多的数据,这些数据还很多样化。
围棋棋谱里说,下围棋都下第二条线,从左右边来讲,从边框来讲第二条线或第三条线,你下第二条线的目的是想要占领对手的角,你下了第三条甚至第四条,你想要占领中间。我小时候自己下围棋,我父亲常常跟我说,中间很小四个角很大,你当然先占四周不要去管中心。结果Alpha Go在跟韩国棋士下的时候,它有一个神奇的下法,他居然下到第五条线去,结果他们Alpha Go自己的工程师都惊讶了,我想韩国棋士也很吃惊有人会下这么蠢的地方,这等于是颠覆了很多棋士的想法。
为什么我觉得这个pipe line(流水线模版)非常有趣生动,《华尔街日报》去年发布了一篇文章,他说Alpha Go可以让我们去研发 IQ超过300的机器,Alpha Go继续再跟自己再下几年棋之后,就等于IQ300的一个棋士。那如果你在其他领域你也可以收集到无限多的数据,那你可不可以研发一个300EQ的医生或者300EQ能够因材施教的老师呢。
实际上最难的都已经做完了,后来到深度学习的时候,我们两个清华学生都做出来了,我们还说不要发布,因为深度学习并行化太容易,结构就这几个,有个人就提议矩阵相乘嘛。我们那时候还想炒掉讲这个创意的人,我说你们就不能有点创新嘛?结果错了,就应该并行,放GPU里面搞就好了。
其实Alpha Go也从去年开始想要从Go到Cure(治疗),那在治病方面,能用这个pipe line(流水线模版)做些什么事情呢,当然有很多限制,第一个限制就是你不能做实验,下棋你们可以有输赢,看病你不能开玩笑。
这个所以“症状检查”的功能现在很多人在用,像在美国大概有二十几个网站跟“春雨医生”类似,很像刚刚讲的增强学习。就问用户几个问题,是否头疼或者是肚子疼,问了几个问题之后,这个所谓的机器就能预测用户生了什么病。
机器可能会问是不是有头疼,然后你说“是”或“不是”,下个问题就不一样了。后面的问题怎么问?我们基本上还是用统计,如果说有发烧症状,我们就匹配发烧的70种疾病,下一个问题最好要缩小到20种疾病,完全可以用刚刚那个增强学习来做。我把主体变成医生嘛,然后把环境变成病人。
美国有26个网站在做“症状检查”,前5名的准确率结果只有35%,听起来很低。哈佛医学院的文章里说,有很多疾病没有验血、验尿、测体温之前,预测35%也不容易。2016我们发布一篇文章,是找100个常见疾病,通过刚刚的pipe line(流水线模版)诊断的准确率可以到50%。
人工智能医疗该走向何处?
B2B比B2C容易
一旦有医疗纠纷B2C一定被告死,当时我们Tricoder(HTC研发的医疗移动检测设备)做出来之后嘛,当时董事会就问准确率多少?我么说百分之八十几,然后就被否决了。也是正常,普通产品99%都有问题,别说八十几还能拿出去卖,但是B2B就没有太大问题,美国的保险公司就很有兴趣。
婴儿如果晚上发烧的话,很多妈妈非常紧张会送急诊室,保险公司2000块美金就少掉了。那我在家里就给你这样一个设备,指导妈妈在家里做一些测试,如果问题不是很严重的话,明天做个常规检查就好,只要200美金,为保险公司省了1800美金。但你要有一个服务中心,至少一个医生和一个护士在后面服务。
另外一个方案也非常有潜力,我下个月到联合国,在非洲很多地方完全没有医疗仪器,有Tricoder(HTC研发的医疗移动检测设备)至少可以做一些测试,加上问诊,至少比把这些人完全丢在那边没有人照顾要好,然后数据再上传到云端,那如果在各国有一些愿意救人行医的在家里就可以看诊了。这些医生不是不愿意,而是说你叫他飞到非洲去,两三周飞一次,那就很难了,但如果说数据都上传了,我在家里可以帮你看一看,那就完全可以。
现在很多地方,包括美国在内,挂个号要排很久的队,可能是小病等成大病了,那如果说在家里或者附近的7-11就可以测一下常规数据,还有一个护士可以帮忙,那大家肯定都乐意。这是一个很大的商机。
还有一个很有趣的事情,在台湾医院,因为全民建保,所以很多人喜欢去医院,最多一年去500多次,对病人来说完全是资源浪费,结果十几年前闹非典,那时候风声鹤唳的,医院怕互相传染不让民众去医院了,反而得流行性疾病的人大大减少。所以有时候没有必要到医院去,在家里可以先检测一下,有很多好处。
大数据共享后的精准医疗
讲一下精准医疗,到底医疗方面有哪些数据可以来做分析?我们刚刚讲Tricoder,那看这张图就可以,这是哈佛大学出来的,Stanford也用。有些数据是相关的,这是结构,有些是双结构,有些是无结构。像诊断数据你在医院可以抓到,还有些叫社会数据,社会网络或者人口统计的数据也可能有用。所以基本上每个人的病例会从不同的地方收集起来,有些是以前吃药的纪录、确诊的纪录,还有一些医生的标注,这些全部都收集起来呢,可以用下一个图去做示例。
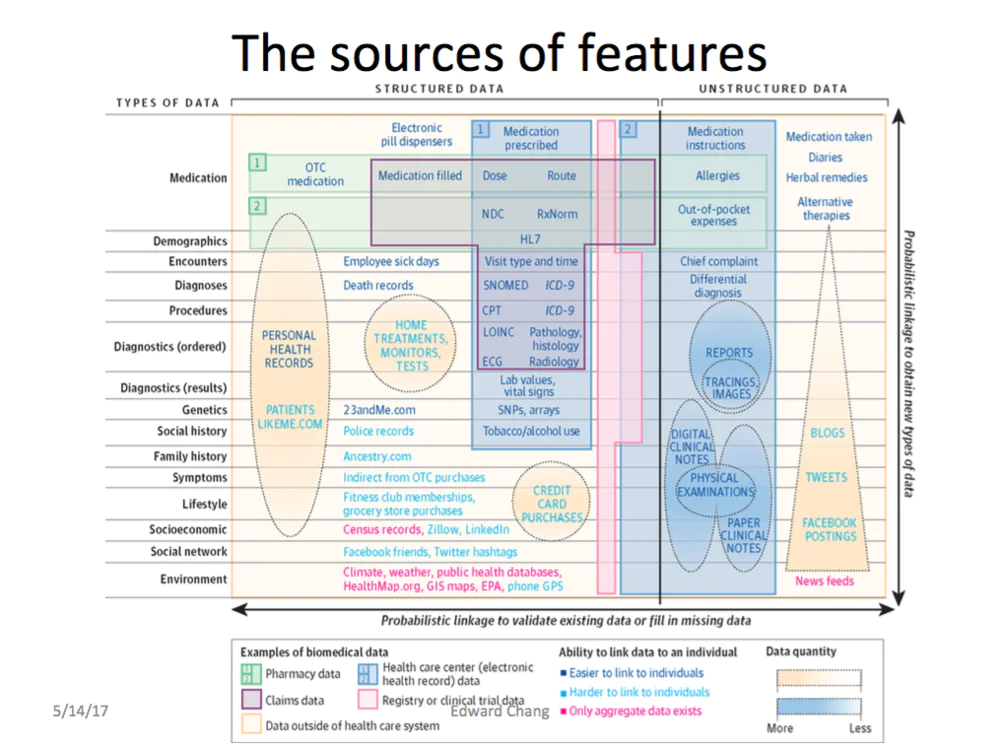
这就等于是每个人的病例,并利用横轴来表示,在某一个时间点的话,到底你在不同的属性上你的值是多少。医疗大数据就是要把这样的纪录建出来,但时间轴上把属性表出来。然后第一个问题就是说,这可能有很多缺失值,缺失值全部填出来之后呢,后面就是大数据的共享了。
全世界哪个地方比较有希望做这样的数据收集呢?、在台湾,因为台湾建保20几年来,一群人每年看500多次病,这也是我在台湾继续做下去的原因。但是司法的关系,数据还不太容易拿到。
VR技术让精准手术成为可能
最后一个话题就分享一个例子,跟大家讲的“精准外科手术”,我们跟UCLA(加州大学洛杉矶分校),跟斯坦福大学已经有深度的密切的合作。就放个视频吧,这个视频是在UCLA拍的,主要是讲怎么帮助手术变得更精准。
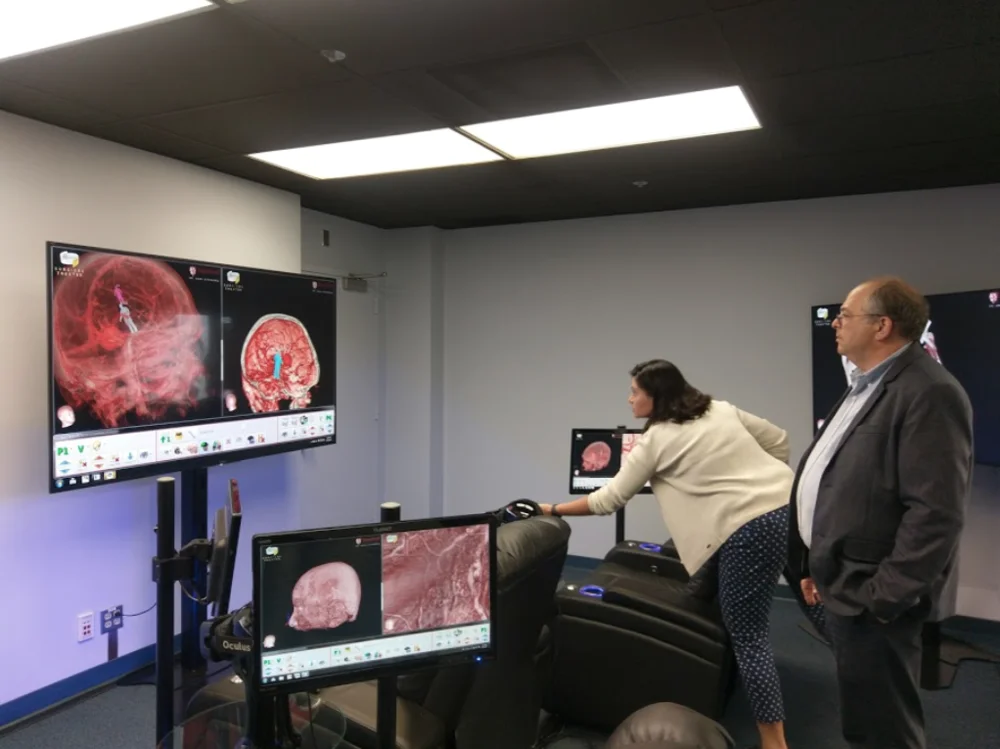
我想大家应该了解了,脑外科手术比想象要难很多。刚开始进这个项目的时候,我们找了很多的医院,我不能把医院名字讲出来,医院A说我们每年开很多脑瘤,有的医生永远从左耳开进去,有的医生习惯从鼻孔开进去,因为他对那个管道非常熟悉。但是他看完这些视频就很吃惊,你如果从鼻孔进去,你到脑瘤之前可能会有一些血管或者是神经,你切掉那些血管或者神经这些人是必死。
你要看肿瘤在哪里,然后找一个最好的路径进去,每个人肿瘤的状况和头部的结构不一样,所以有没有VR会差得非常多,除了刚刚讲的制定手术方案之外,你还可以先做手术练习。
更重要的一点是,现在病例很多,如果有人工智能系统,新病人进来直接在病例里面找到新的病例跟以前哪个病症最像,那个病人我是怎样把他治好的,马上可以出来一个手术方案。即使是非常初级的手术也可以用,这绝对可以救很多人。
这个大家可以看到,好处显然很大,神经可以做得好的话接下来就是腹腔开刀。腹腔进去很容易碰到动脉血管或者是尿管,切错血管还不至于死,还可以用电极把它接起来,但是切断尿管就结束了。现在可以在切到尿管之前,在皮层的时候有个信号出来说这是尿管,所以刀不会切下去。
最后要跟大家展示的就是Vive paper,Vive paper,我们把Vive系统前面这个摄像头打开,可以直接互动。所以下面一张图大家可以看到是,手上拿着一张纸,纸上一些标记,然后我们把虚拟内容做到这张纸上面,点进去可能就是一个VR场景,或者是一个3D或者360度的视频。这个平台可以用来做很多的事情,如果把这本书改成一个解剖的教案,这对于医疗教学是很棒的。

评论